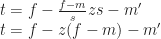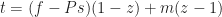I sometimes get emails about Text Collector asking something like, “How long does it take? I’ve been waiting more than an day.” Or, “My collection keeps saying ‘Interrupted,’ what do I do?” These look like symptoms of the phone pausing or killing my app, and my gut says they’ve been coming more and more in the five years since I released it. I’m not alone in my suspicion:
We see a reverse evolution of Android. Every new version is less capable than it’s predecessors. Petr Nalevka at Droidcon 2022
Have Petr and I fallen into the trap of looking at the past through rosy glasses, or is this true? I am that guy who thinks newfangled JavaScript mostly just makes simple things complicated, but this time, I have data.
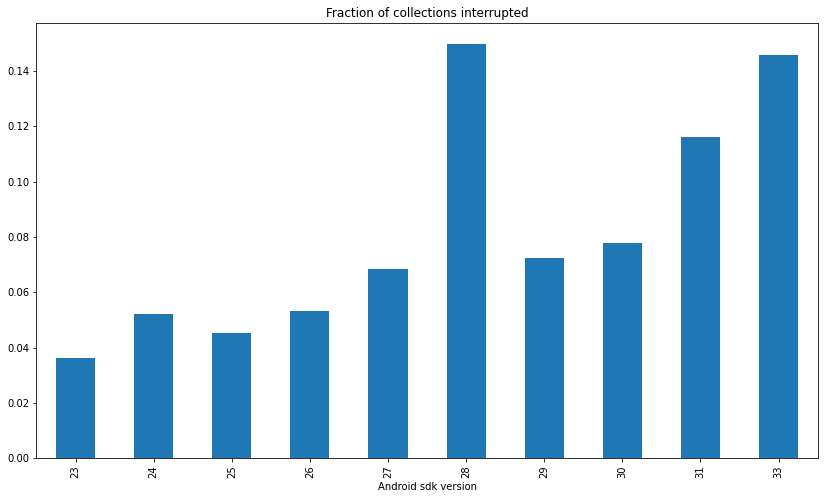
In this chart, the x-axis represents increasing Android versions from “sdk version code 23,” (Android 6) through sdk version code 33, (Android 13). Lower is better, so it’s trending worse.
When you start a collection, Text Collector copies your messages and arranges them into documents, all of which takes time and I have an idea how much time because you can choose to report anonymous telemetry to me. Successful collections usually finish in less than five minutes; they typically take one second per 500 plain text messages or 20 picture messages, though the timing varies widely.
Android isn’t like a movie villain who explains his scheme before killing you: if you’re an app Android wants to kill, you get no warning, but Text Collector can see remnants of unfinished collections when it starts and infer that it was killed during collection. I count each unfinished collection as an interruption, so the chart above shows the proportion1 of interrupted collections increasing steadily from four percent in Android 6 to 14% by Android 13, with a notable spike in Android 9 that we’ll revisit.
This is a huge problem for the hapless folks using Text Collector on increasingly modern Android. Today, more than one in ten collections fail because something aborts them.
The something aborting collections can be either human, or Android of its own accord. I can’t differentiate which was which directly, but it seems implausible that people using Android 8 are twice as patient as those using Android 12. A plausible reason to pin these on the user might be that if Android has gotten slower, collections could be taking longer and that might provoke people to stop them more often. My collection timing data, however, doesn’t show a clear trend to collections getting slower over time. So the most plausible reason for increasing interruptions is that Android is doing it without user consent.
In other words Petr Nalevka was right: newer versions of Android mostly appear less capable of archiving your messages than their predecessors.
By brand
In the second half of his talk, Petr moves from blaming this trend on Android proper to the various manufacturers, and if you visit https://dontkillmyapp.com/, you’ll see Samsung ranked as worst, Google and Nokia best. Does my data agree? In a couple words, not really:
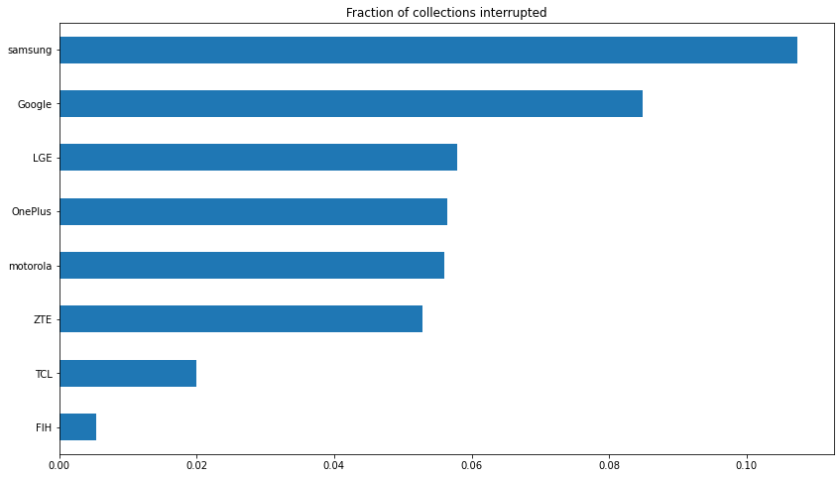
Looking at the same metric, fraction interrupted, by manufacturer, Samsung indeed ranks worst, but Google comes in second to worst. This view, however, is a little too simplistic. Breaking it down further, we can see that this ranking depends on Android version:
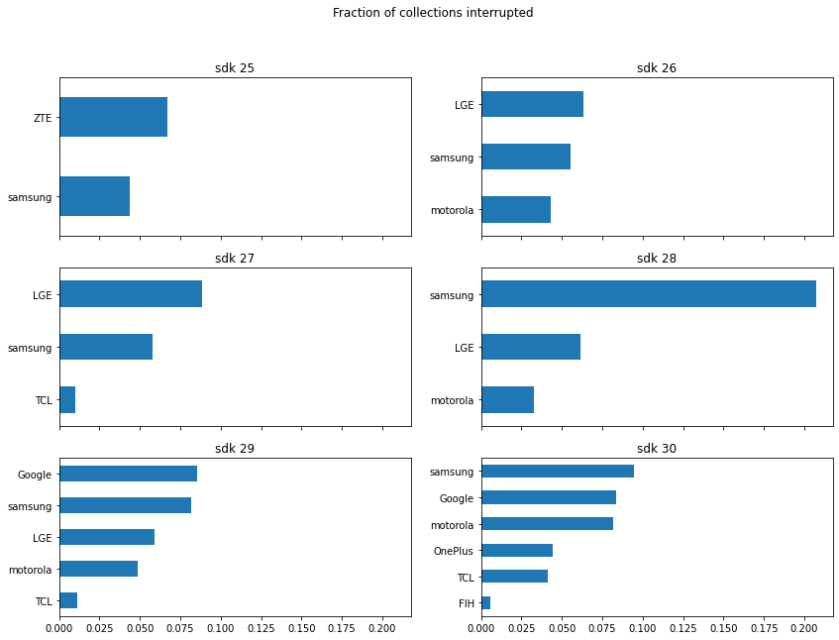
I’ve restricted this to only those combinations of sdk version and brand that have at least 500 collections, so it covers a smaller span of sdk versions, but reveals more nuance.
First, we can blame the apparently disastrous performance of sdk 28 (Android 9) on Samsung: Samsung did something in that version that aborted collections much more often than in any other scenario, and because Samsung phones are so common, it hurts the average for all Android 9 phones.
Second, although Don’t Kill My App endorses the idea that we can blame this on the Chinese, there’s no evidence in this data that Chinese brands are worse than any other. Only two of the brands I show here are Chinese, Zte and Tcl and if anything, they look better than most. If I reduce the threshold to only 200 collections, there is a scenario where Huawei does worse than Google, but that sample is so small I hesitate to infer anything from it.1
Which brings us to the final point: if anything, Google is among the worst offenders, not the gold standard.
Don’t Kill My App disagrees, ranking Samsung as most likely to kill your app and Google as least likely. The difference may partly be because their interest is different from mine: they focus on low-power background tasks like alarms and health monitors whereas Text Collector is doing a job that’s inevitably power-intensive. Another problem, however, is that Don’t Kill My App ranks manufacturers subjectively:
The info on the site is gathered from multiple sources. The big part is from the experience of the Urbandroid Team, but increasingly info is added from FAQs of other developers, and from personal experience shared on the GitHub repo. Ibid.
For a more objective measure, Don’t Kill My App also provides a benchmark app, but I’ve run it several times on a couple Samsung phones and it scored a perfect 100% on both. I find that hard to reconcile with ranking Samsung as the worst offender. I suspect Samsung ranks worst because Samsung makes most Android phones; if a problem is inherent to Android, therefore, it’s most likely to be seen on a Samsung phone.
Does it matter?
Choices are good. We might all benefit from variety and competition if prevailing information about strengths of each brand were based more on facts than rumor. Instead of “reverse evolution,” survival of the fittest.
The freedom to change the program is Essential Freedom 1, but Open Source often doesn’t relish this freedom: the mainstream view in the Android community says that diversity – under the pejorative “fragmentation” – is a bad thing. Sycophantic headlines like “Google is finally helping developers fight back against smartphone manufacturers” play into Google’s narrative. Google want us to see Google as white knight: benevolent stewards of a healthy ecosystem. Meanwhile, they make Android measurably worse, year after year.
The truth is that the manufacturers, possibly excepting Samsung, are just as much Google’s victims as app developers. We’re all clinging to a raft called Android while Google shoots holes in it.
What can be done?
First, appealing to Google won’t help: that comes from the “fool me 13 times, shame on me,” school of thought. Why should Google care? From their perspective, a phone doing something other than showing ads is wasting cycles. Crippling Android is, in some ways, useful to Google: it gives their own privileged applications an advantage. But in the spirit of never ascribing to malice what can be explained by incompetence, even if they did care, they demonstrate all the symptoms of having no coherent idea how Android ought to behave.
Which brings us to the second tactic that won’t help: the “Compatibility Test Suite.” These types of errors are devilish to reproduce in controlled environments: the error statistics I’ve presented above clearly show a problem in the wild, but one I have never seen on a phone that I’m using. Likewise, the Don’t Kill My App benchmark doesn’t repeatably support the rankings on its site and Sms Backup+, which does something more like what Text Collector does, has much conjecture on the causes of a related problem, back and forth “works for me,” “doesn’t work for me…” This is typical of building on a system that is over its programmers’ complexity horizon: having never developed a clear plan, it’s impossible for the Android developers to implement a comprehensive test suite.
Both of the strategies above also reinforce Google’s monopolistic rhetoric. Google isn’t competing with Apple – that duopoly is too cozy to disrupt – Google is competing with the Android manufacturers, a space where its Play Store monopoly gives it such leverage that, but for fear of making it too easy for antitrust regulators to gather evidence of their tactics, they should have been able to squeeze out the oems already. In the long term, the most obvious step is for regulators to break up Google so that Android has to compete on merit, which requires political will from a public understanding that Google is the root of Android’s problems.
For Text Collector’s near future, I have to change something to complete more collections for more people. Probably I’ll have to shove a notification into the top of the screen. Right now, Text Collector uses a Wake Lock in a Thread without a Service and some will say, that’s the problem: that I’m doing it the “wrong way,” so the fault is my own, not Google’s. That’s a facile objection based on a selective reading of the documentation and I may dive deep into why another time. For now, though, it’s clear that if I’m guilty of something, it is that I’ve been the proverbial frog in the water in failing to deal with this increasing problem.
Notes
- “Successful” but empty collections excluded as I assume they are mostly app crawlers.
- I’m not sure how to put confidence intervals on these numbers: the big problem is that these aren’t independent observations. I don’t collect anything that links a report to a particular person, so it’s likely that many of these reports are clusters of a single person trying multiple times and being interrupted multiple times. I do record retries, though, and that suggests that the fraction of interruptions retried doesn’t significantly vary by brand.
Archive links
Don’t Kill My App Droidcon
Don’t Kill My App
Don’t Kill My App’s mission statement
Anti-Chinese bug report
Essential freedoms
Google-loving article
Android privileged applications
Sms Backup+ bug report







 .
. : focal point of the zoom, window units
: focal point of the zoom, window units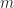 : margin outside the content, window units
: margin outside the content, window units : starting scale, window units per content unit
: starting scale, window units per content unit : scale factor, that is, change in scale, unitless
: scale factor, that is, change in scale, unitless : margin after scaling, window units
: margin after scaling, window units : scale after scaling, window units per content unit
: scale after scaling, window units per content unit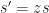
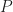 : pivot around which scaling happens, content units
: pivot around which scaling happens, content units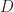 : content that aligns with the zoom focal point when zoom begins, content units
: content that aligns with the zoom focal point when zoom begins, content units
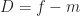 .
.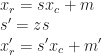
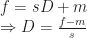
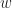 : position of the pivot,
: position of the pivot,  .
.

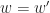 . This implies:
. This implies:
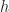 : position of the content at
: position of the content at 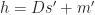

 . Recalling that
. Recalling that